Rekomendacje produktów i churn w ubezpieczeniach
System rekomendacji + model churn
Rekomendacje produktów ubezpieczeniowych i predykcja churnu.
Opis projektu
Celem było stworzenie produkcyjnego systemu przewidującego zachowania zakupowe klientów oraz modelu prognozującego prawdopodobieństwo rezygnacji z polisy w kolejnym roku.
Przegląd
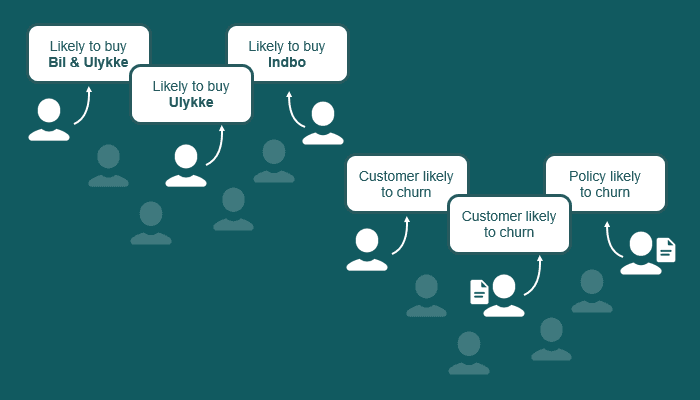
Branża ubezpieczeniowa w Danii intensywnie poszukuje zastosowań ML i analityki danych, jednak niewiele firm realnie usprawnia procesy. W ramach współpracy TIA Technology z klientem zbudowaliśmy system rekomendacji oraz model churnu, który miał wnieść mierzalną wartość biznesową. Do rekomendacji użyliśmy KNN i sieci neuronowej, a do churnu – LSTM i XGBoost.
Poniższy gif pokazuje integrację platformy front‑end z API ML. Predykcje zmieniają się, gdy do profilu klienta dodawany jest produkt.
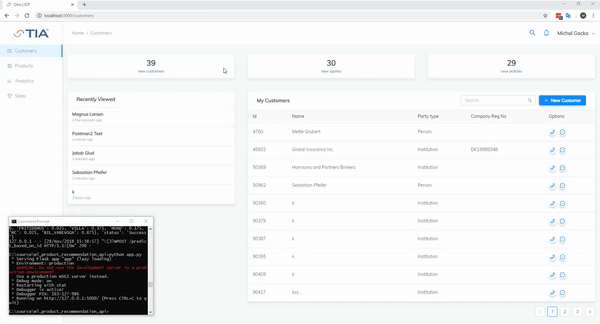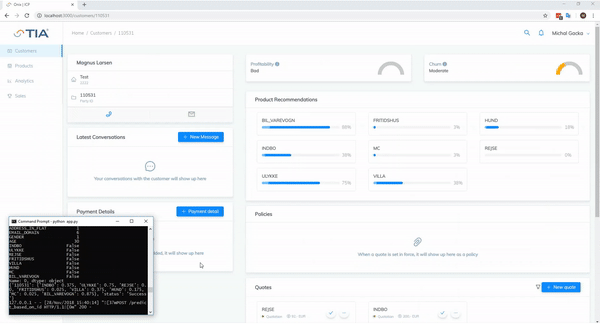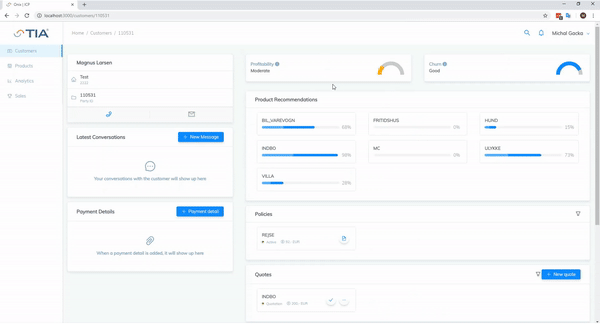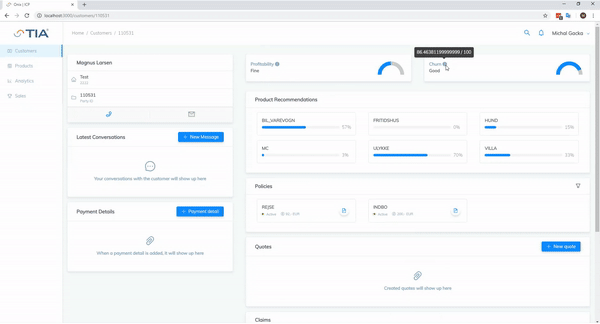
Szczegóły techniczne
Pracujemy głównie na danych z hurtowni przygotowanej przez dział BI. Transformacje wykonujemy w Pandas, rekomendacje w Sklearn, a modele czasowe w Keras. Slajdy pochodziły z prezentacji dla klienta.
Rekomendacje produktów
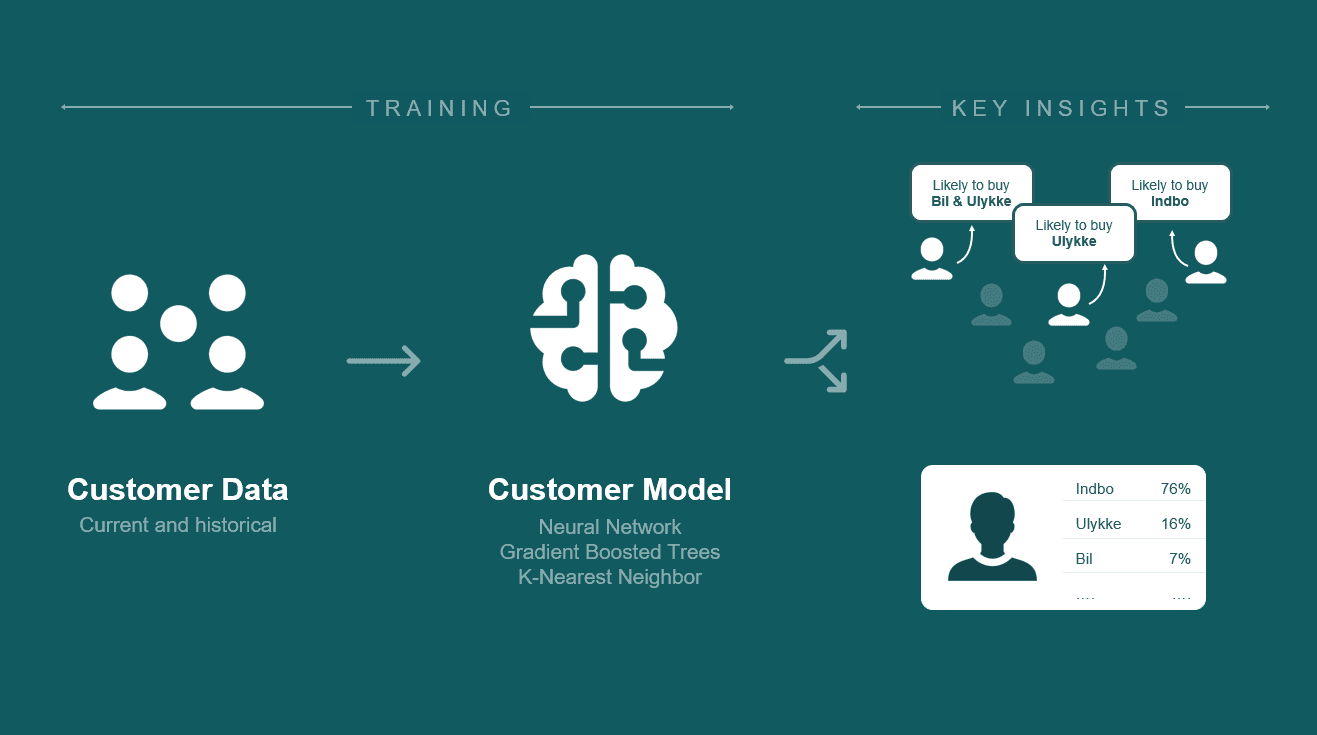
System rekomendacji składa się z dwóch części: KNN dopasowuje klientów do najbliższych sąsiadów, a sieć neuronowa obsługuje nowych klientów. Wykorzystujemy XGBoost do interpretacji ważności cech.

Churn

Model churnu działa na poziomie polis. Dane szeregów czasowych pozwalają przewidzieć prawdopodobieństwo nieprzedłużenia polisy. Jako baseline użyliśmy liniowego XGBoost, a następnie próbowaliśmy poprawić wynik przy użyciu RNN.
Mój wkład jako ML Software Engineer
Byłem zaangażowany w cały pipeline – od danych w CSV, przez eksperymenty i budowę modeli, po komunikację z klientem i wdrożenie API.
Zbudowałem modele rekomendacji i churnu oraz stworzyłem API Flask do retrainingu i ekspozycji predykcji. Zintegrowałem je z frontendem i użyłem docker‑compose do wersji demo.